Подчиняем себе звук! Работаем с .wav файлами.
Откуда берется звук?
В этой главе мы с вами научимся работать со звуком с помощью Python и создадим приложение, которое будет реагировать на голос пользователя и передразнивать его, искажая исходную фразу.
Но прежде чем мы начнем, нужно понять, что такое звук и откуда он берется.
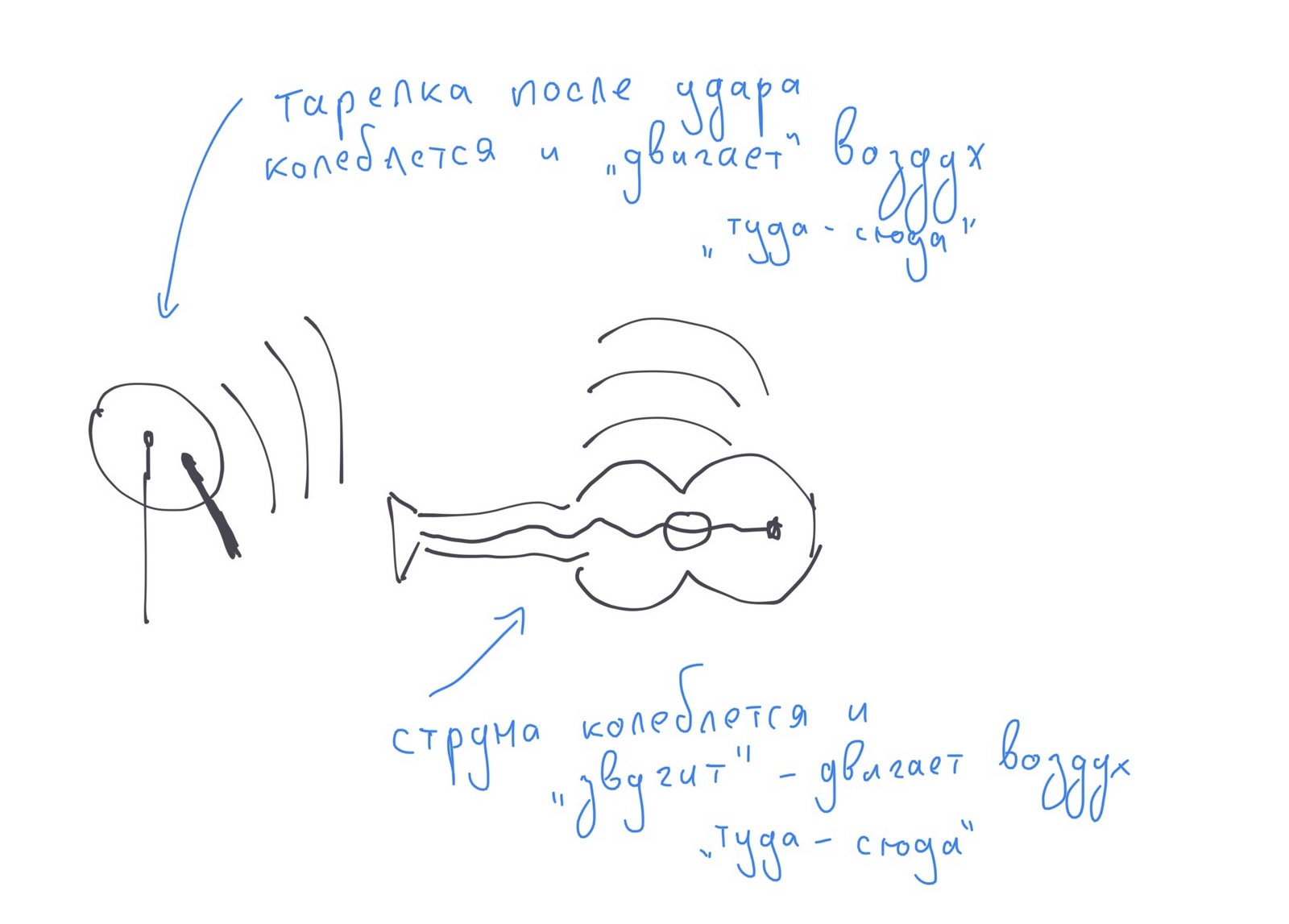
Звук, который мы слышим с помощью наших ушей - это колебания воздуха (изменение его давления), которые "двигают" туда-обратно барабанную перепонку в нашем ухе. Если воздуха (или другой среды для передачи колебаний, например, воды) не будет, то не будет и звука.
Издают эти колебания быстрые движения различных объектов, например, вибрация барабанной тарелки, колебания струн гитары или пианино (там тоже есть струны, при нажатии на клавиши по ним бьет молоточек), колебания натяженных голосовых связок в нашей гортани.
Звук в компьютере воспроизводится с помощью динамиков (в которых движется натянутая мембрана), а записыватся с помощью микрофона (который считывает движение мембраны внутри и переводит их в электричество).

Если мы отобразим на графике изменение давления воздуха (те самые колебания), то у нас получится звуковая волна. По вертикальной оси - изменение давления, или амплитуда колебания, а по горизонтальной - время.

Частота и амплитуда
У звука есть две важные характеристики, которые отвечают за его восприятие - громкость и высота. Мы легко отличаем громкий звук от тихого, а плач ребенка от гула двигателя.
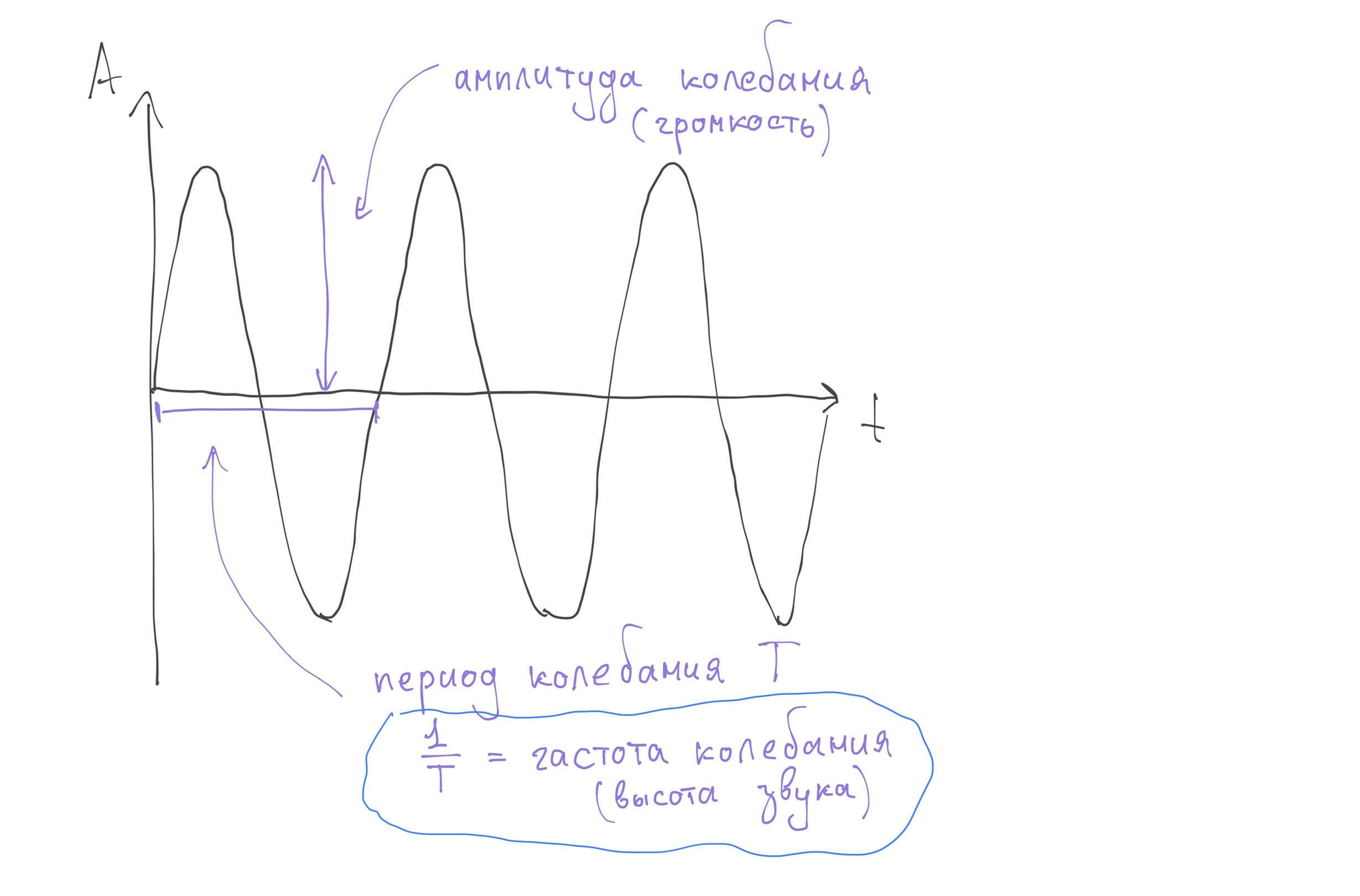
За громкость на графике звуковой волны отвечает амплитуда. Чем выше отклоняется колебания от нуля (обычного давления воздуха), тем громче воспринимается звук. Причем амплитуда может быть как положительной, так и отрицательной, но нам важно именно отклонение от нуля. Чем больше амплитуда, тем громче звук.
А за высоту звука отвечает частота колебаний. Чем чаще объект двигается "туда-сюда", чем чаще он колеблется, тем выше получается звук. Математически выделяют понятие периода колебаний - время, за которое колебание достигается максимума, затем минимума и возвращается к нулю. Период измеряется секундах.
Частота - это величина обратная периоду (один делим на период), измеряется в 1/с - герцах.
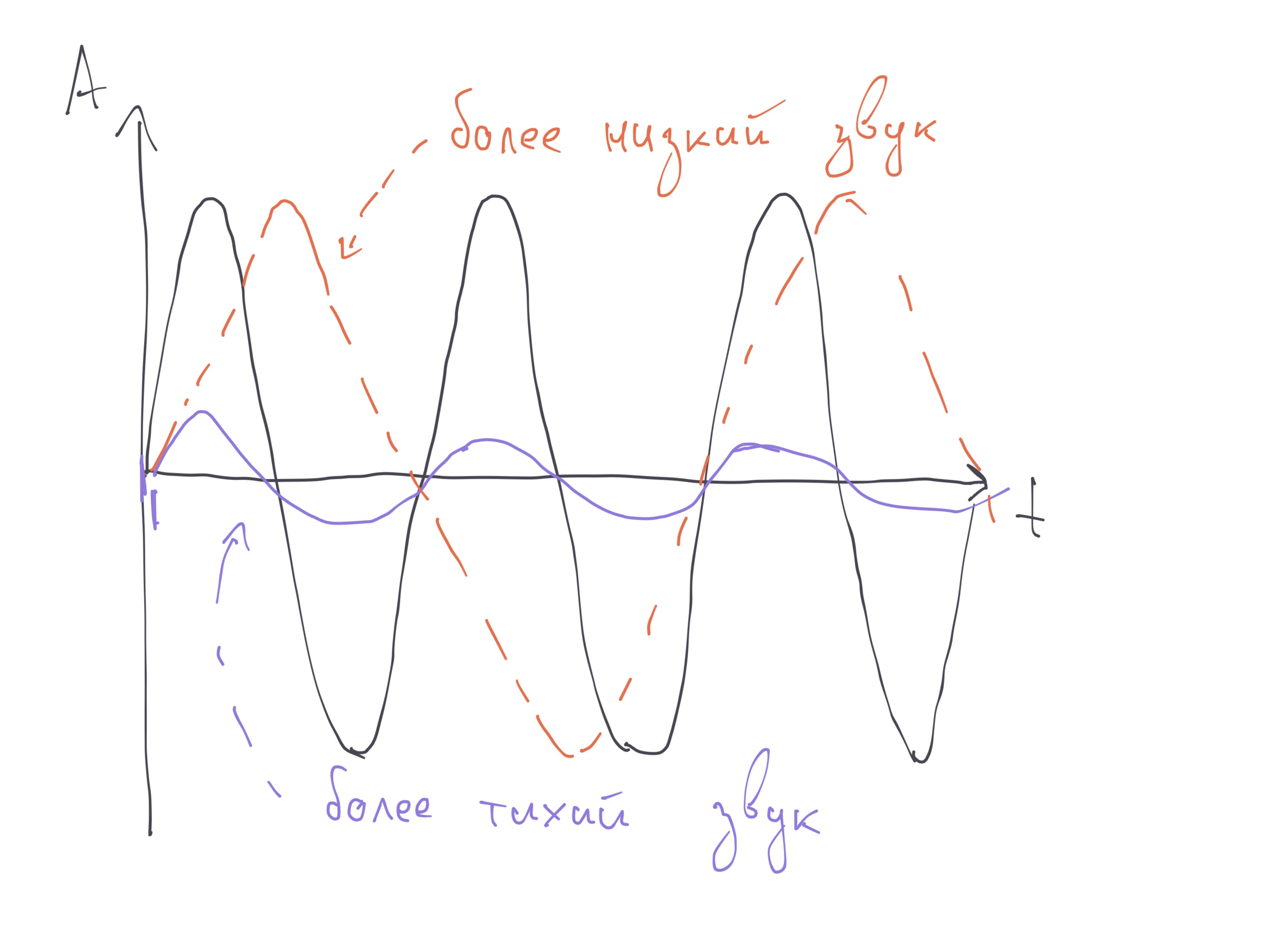
Выше пример трех волн на одном графике. Фиолетовая волна тише черной, но такая же по высоте, а оранжевая по громкости равна черной, но звучит ниже.
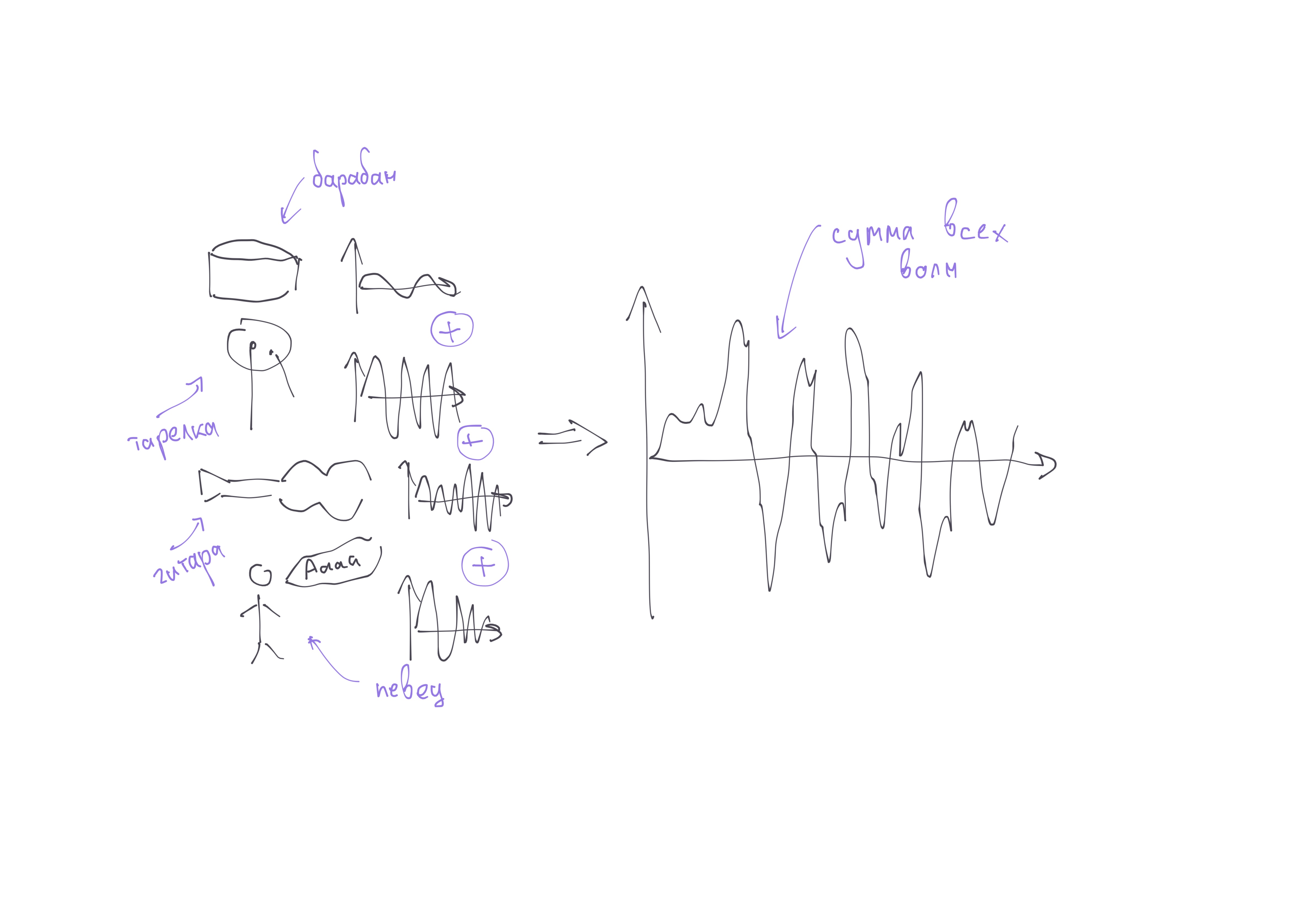
В реальности человек одновременно слышит множество источников звука, которые издают одновременно и высокие и низкие звуки. Поэтому волна, которая "приходит" к нам в уши - выглядит не как синусоида, это сумма большого количества волн, а разбиением на части занимается наш мозг.
Оцифровка звука
Для того, чтобы сохранить звук на жесткий диск, его нужно представить в виде какого то конечного набора чисел. Такой процесс называется дискретизацией.
Для этого нам потребуется разбить время и амплитуду на маленькие отрезки, и зафиксировать значения амплитуды волны в каждый момент времени.
Т.е. другими словами, идея в том, чтобы много раз в секунду фиксировать значение амплитуды волны и записывать на "листочек". А когда потребуется воспроизвести звук - нужно будет по этим записям "нарисовать" исходную волну. Ну или по-крайней мере очень похожую на исходную.

Одно значение амплитуды на такой сетке называется - семплом, отсчетом или фреймом (в разных местах по разному). Главное, что все это - значение амплитуды (громкости) звука в конкретный момент времени.
Количество делений, на которые мы делим ось амплитуды связано с глубиной звука (sample width, размер семпла).
Глубина звука (sample width) - это количество памяти, которое отводится на хранения одного значения амплитуды, измеряется в битах или байтах.
В старых играх вы скорее всего встречались с восьмибитным звуком. В таком звуке для хранения одного значения амплитуды уходит 8 бит, а значит ось амплитуды поделена на 256 делений (8 бит = 2 ^ 8 комбинаций = 256 вариантов громкости), половина уходит на положительные, другая половина на отрицательные значения. Из-за того, что значений мало и точно зафиксировать громкость не удается, такой звук звучит "угловато".
В большинстве файлов вы слышите звук с глубиной 16 бит. Это 65536 делений на шкале громкости (2 ^ 16 вариантов), и этого вполне хватает, чтобы точно передает громкость. В некоторых форматах встречается и большая глубина звука - 24 бита и даже 32 бита, но это используется для воспроизведения звука на очень хорошем оборудовании, либо в процессе записи звука и наложения эффектов звукоинженерами.
Количество делений, на которые делится одна секунда записи называется частотой дискретизации (framerate, частота кадров / семплов). В большинстве звуковых файлов вы столкнетесь с частотой дискретизации 44100 герц, это означает, что каждая секунда состоит из 44100 семплов (измерений громкости).
Устройство, которое превращает волну в набор семплов (измеряет и записывает громкость framerate раз в секунду) называется аналогово-цифровым преобразователем - АЦП. А обратный процесс - восстановление звука по набору его громкостей - это обязанность цифро-аналогового преобразователя (ЦАП). Оба этих устройства встроены в звуковую карту в вашем компьютере и телефоне.
Уменьшение частоты дискретизации или глубины звука ухудшит качество звука, т.к. при оцифровке будет возникать много ошибок и ЦАП не сможет точно восстановить исходную волну по набору точек.
P.S. Описанный выше способ оцифровки называется импульсно-кодовой модуляцией (PCM). Существуют и другие способы оцифровки звука, но они использутся гораздо реже.
Моно, стерео и многоканальный звук
Когда мы слушаем музыку с телефона или компьютера, то чаще всего мы используем наушники или два динамика, в которых одновременно для каждого уха уха воспроизводится свой сигнал. Это позволяет нашему мозгу определять расстоние до источников звука и тем самым формировать звуковую сцену (понимать, что вокалист ближе, бараны дальше, а гитара слева). Такая музыка, в которой храниться разный сигнял для левого и правого уха называется стерео звуком.
Если в файле наоборот храниться только один сигнал для обоих ушей, то это моно звук. А в кинотеатрах часто используют сразу много колонок (5, 7 или даже 9 + сабвуфер для низких частот), для каждый их них своя звуковая дорожка, и это называют многоканальным звуком.

Количество разных звуковых дорожек внутри одного аудиофайла называют количеством каналов.
В моно файле 1 канал, в стерео 2, в 5.1 фильме их 6.
Сколько весит звук? Разные форматы и сжатие
Давайте попробуем посчитать, сколько памяти должна занимать стерео-композиция длительностью в 3 минуты с частотой дискретизации в 44100 герц и глубиной звука в 16 бит.
- 3 минуты - это 180 секунд.
- Каждая секунда - это 44100 семплов.
- Каждый семпл - это 16 бит.
- Стерео звук - это две дорожки, значит размер удваивается.
Размер файла = 180 (секунд) * 44100 (семплов) * 16 (бит) * 2 (канала) = 254 016 000 бит = 30,3 мегабайта.
30,3 мегабайта - это довольно много! Скорее всего вы привыкли, что такой файл обычно занимает около 6 мегабайт или даже меньше. Почему наши расчеты не сходятся с реальностью? Дело в том, что в реальности к звука применяются алгоритмы сжатия.
Звук в несжатом ввиде храниться в формате .wav (.aiff у Apple). И в нем стерео файл на 3 минуты правда весит 30 мегабайт. А 50 минут звука на CD диске как раз займут примерно 700 мегабайт места (весь CD диск).
Чтобы сделать файлы меньше их можно сжать. Сжатие звука бывает двух видов - с потерями и без потерь.
Сжатие звука без потерь позволяет уменьшить размер файла, а затем вернуть его в исходный вид без искажений. Например, так умеют форматы .flac / .alac / .ape. Но размер файла в этих форматах все равно будет большим - около 15 мегабайт (файл уменьшается примерно в два раза).
Чтобы уменьшить размер файла еще больше, придется пойти на компромисы, например, откинуть из файла частоты, которые человек не слышит или слышит плохо. В итоге сжатый файл будет немного отличаться от исходного, но так, чтобы разница была плохо заметна человеку. Такой подход называется сжатием с потерями, так умеют форматы .mp3 / .ogg / .aac и другие. В зависимости от степени сжатия от файла mp3 можно добится и 6ти мегабайт (в хорошем качестве) и размера меньше мегабайта (с ощутимыми потерями).
Работаем с wav файлами
Мы с вами будем работать с звуком в формате wav. Звуковой файл в wav - это бинарный файл, который состоит из заголовка с информацией о файле (глубина звука, частота дискретизации, количество каналов и семплов, а также другая техническая информация) и последовательности семплов амплитуды.
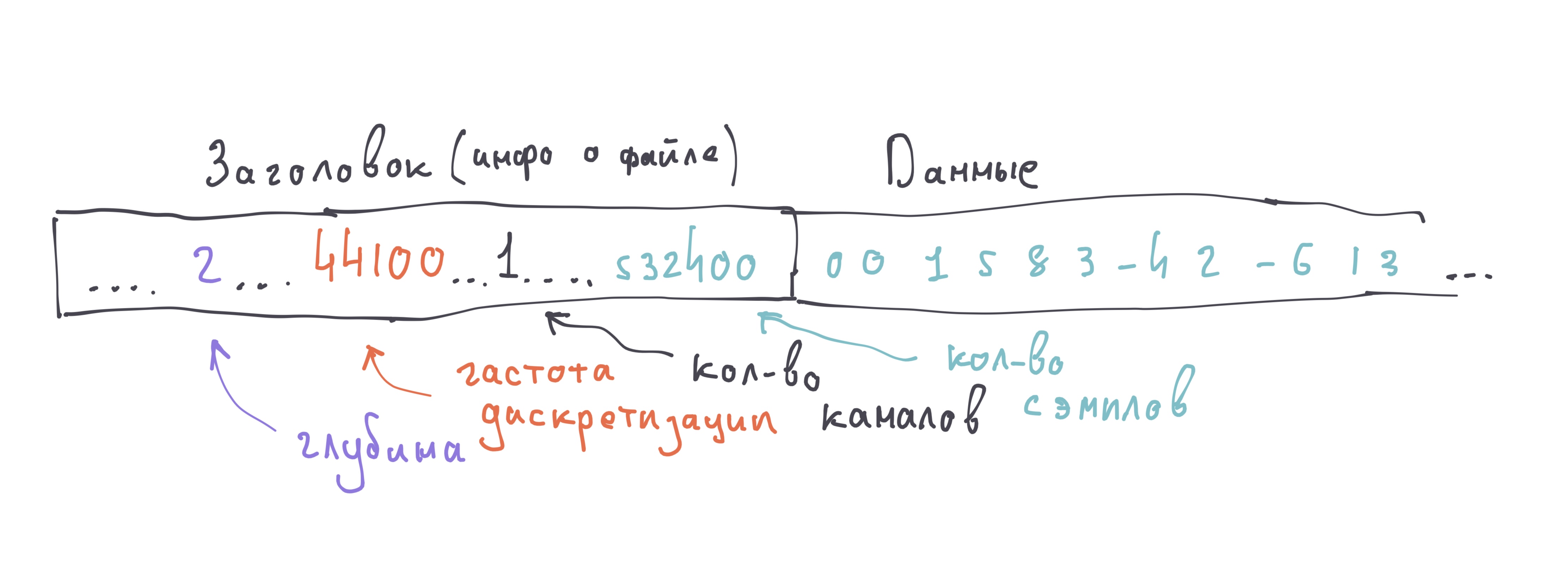
Для работы с ним мы будем использовать встроенную в питон библиотеку wave. В отличии от pillow, wave - это довольно низкоуровневая библиотека, которая будет читать семплы из файлав формате байт строк - набора байтов, а перевести их в числа нам потребуется уже самостоятельно. Для этого мы используем библиотеку struct (тоже встроена в питон).
С чего начать? С открытия файла и чтения его параметров. Для примера можно взять вот этот файл.
import wave
audio_file = wave.open("song.wav")
SAMPLE_WIDTH = audio_file.getsampwidth() # глубина звука
CHANNELS = audio_file.getnchannels() # количество каналов
FRAMERATE = audio_file.getframerate() # частота дискретизации
N_SAMPLES = audio_file.getnframes() # кол-во семплов на каждый канал
print("Глубина звука:", SAMPLE_WIDTH)
print("Количество каналов:", CHANNELS)
print("Частота дискретизация:", FRAMERATE)
print("Количество семплов в файле (на каждый канал):", N_SAMPLES)
# зная кол-во семплов, количество каналов и частоту дискретизации, можем вычислить длительность звука в секундах
print("Длина композиции:", N_SAMPLES // FRAMERATE , "сек")Все каналы лежат в одном файле, причем значения семплов левого и правого каналов записаны парами: семпл_левого_канала семпл_правого_канала семпл_левого_канала семпл_правого_канала....
Глубина звука: 2
Количество каналов: 2
Частота дискретизация: 48000
Количество семплов файле (на каждый канал): 10178143
Длина композиции: 106 секТеперь попробуем прочитать из файла все семплы и положить их в переменную (а заодно определим ее тип).
samples = audio_file.readframes(N_SAMPLES)
# выведем тип переменной
print(type(samples))
# и первые 10 ее элементов
print(samples[:10])Как мы видим, семплы возвращаются в формате байт-строки, и если мы хотим получить список чисел, это нужно сделать отдельной операцией.
<class 'bytes'>
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'Чтобы превратить байты в список чисел, используем библиотеку struct.
import wave, struct
# открываем файл для чтения
audio_file = wave.open("song.wav", "rb")
# узнаем кол-во семплов в нем
N_FRAMES = audio_file.getnframes()
# узнаем кол-во каналов
CHANNELS = audio_file.getnchannels()
# читаем из файла все семплы
samples = audio_file.readframes(N_FRAMES)
# просим struct превратить строку из байт в список чисел
# < - обозначение порядка битов в байте (можно пока всегда писать так)
# По середине указывается общее количество чисел, это произведения кол-ва семплов в одном канале на кол-во каналоов
# h - обозначение того, что одно число занимает два байта
values = list(struct.unpack("<" + str(N_FRAMES * CHANNELS) + "h", samples))
# выведем тип переменной
print(type(values))
# и первые 10 ее элементов
print(values[:100])<class 'list'>
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]Почему в начале нули? Видимо, в начале файла тишина.
Потоковая обработка звука из файла
Теперь попробуем поменять звук, например, сделаем более тихую копию файла. Для этого нам понадобится разделить каждое значение амплитуды на какоениубдь число. Например, на два.
import struct
import wave
# открываем файл из которого мы будем брать звук для чтения (read binary)
input_file = wave.open("song.wav", "rb")
# создаем пустой файл в который мы будем записывать результат обработки в режиме wb (write binary)
out_file = wave.open("quite_song.wav", "wb")
# узнаем кол-во семплов и каналов в источнике
N_SAMPLES = input_file.getnframes()
CHANNELS = input_file.getnchannels()
# в "настройки" файла с результатом записываем те же параметры, что и у "исходника"
out_file.setframerate(input_file.getframerate())
out_file.setsampwidth(input_file.getsampwidth())
out_file.setnchannels(CHANNELS)
# читаем содержимое из файла все семплы в виде последовательности байт и превращаем их в список чисел
samples = input_file.readframes(N_SAMPLES)
values = list(struct.unpack(f"<{N_SAMPLES * CHANNELS}h", samples))
# каждое значение амплитуды в списке уменьшаем в два раза
for i in range(len(values)):
values[i] //= 2
# обратно перегоняем список чисел в байт-строку
audio_data = struct.pack(f"<{N_SAMPLES * CHANNELS}h", *values)
# записываем обработанные данные в файл с резхультатом
out_file.writeframes(audio_data)